This is part two of the building production software short series. Bear with me, this is a tedious one. And it’s full of words such as “latency”, “ETL service“, “traffic spikes”, “binlog files”, etc.
I promise you though, it is worth the reading. We’ll save the best for last and we will talk NUMBERS. That is, decreasing the hardware’s bill for the client. With percentages. And, so long as we write about them, as you already figured, they are really good numbers to show-off.
The “task“
Client says it’s a task. That of reducing their bill. We agree. But to make it so, we needed to build an entirely new system stack. We’ll call it evs processing service.
Mind you, this is part of our consulting job we do for all of our clients. This requirement was proposed and volunteered by us to the client. The client said, oh, ok, so you are reducing our AWS bill. I am giving you the approval to add and customize this service to my software.
So, here is what the “task” should solve:
- Be built for big data; we were expecting to get 200k+ req / sec
- Be fast for any possible http client; any HTTP request should take as little as few milliseconds (1-3 ms) to complete
- Making it fast gives us a low CPU consumption, thus creating room for handling even more concurrent http requests
- Protect data against process failure (e.g. “kill -9” won’t lose precious events)
- Provide a specific protection layer for “complete server failure” (e.g. power outage); data loss should be limited as much as possible
- Use custom binlog files to assure recovery procedures
- Any subsystem from our stack can go down, without disrupting the natural flow of the events. For instance, it will continue to work for many hours even if the backend data-source is down (being it a Cassandra, mongoDB, MySQL). Enough just to bring the data source up and the data will be synced at once.
- Handle spikes. And we mean sudden spikes, like 40-50% of total traffic.
- Work well with slow and multiple concurrent connections (e.g. mobile users).
- Provide meaningful live stats (how many events, how many seconds behind, is data warehouse up and running, queue size, etc.)
- Make it truly hardware cost effective; we aimed for running it under a 4-cores compute optimized ec2 instance
- Have data backup processes (using amazon s3)
- Provide integrity checking and administration tools. Why should we need this? Because sometimes things can go wrong. And because we need to prepare for human error. However, this is the subject of another blog post by itself.
Event flow
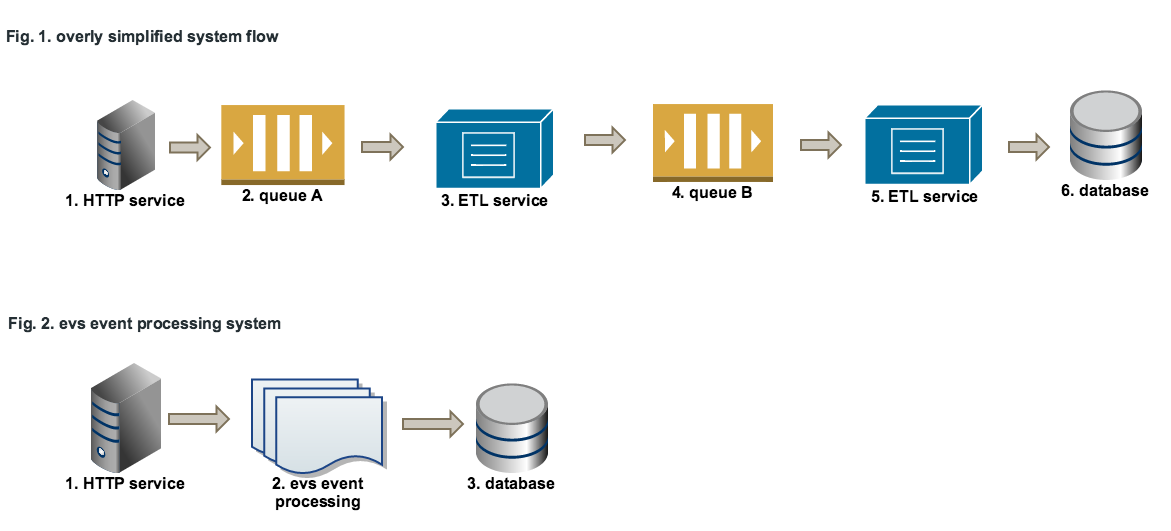
Our service stack (this is all):
- nginx (any other web server will work),
- evs event processing service
- mongodb
Having steps 2, 3, 4 and 5 from Fig.1 into one single processing service significantly increases the performances, as further detailed.
Benchmarks – technical perspective of the system
Environment:
- xlarge (4 cores) & EBS storage
- Ubuntu 14.04.1 LTS 64-bit
- nginx 1.6.2
- mongodb 2.6.4
Results:
- The stack works great at 20k req/sec; the load average is below 2.0;
- What about spikes? The system continues to provide great results even at 30k/sec, although the latency starts to increase a little bit. But not too much, after all we discuss about 0.5–1ms latency. Also, flushing data to the storage engine starts to be delayed by several sec every 5 min. When the spike goes away, the system catches up very fast.
Money Savings – business perspective of the system
For the client, the cost drop was significant:
- The old setup was costing the client 100 % per month ($)
- The new setup is costing the client 13. 48 % per month ($)
- Cost drop: 86. 52 % per month ($)
Plus, the new setup can support 30%-40% more traffic without adding new servers. That is, the new 13. 48 % per month ($) bill can now scale up to 30 – 40 % more traffic with no additional costs whatsoever.
Obviously, we cannot put in actual bill values due to confidentiality terms. But, this kind of consultancy, that translates solid coding methodologies into money savings, is something we can do very well for all of our clients.